
👋 About Me
I am currently a final-year Master’s student in Computer Technology at Tsinghua University, under the supervision of Prof. Chun Yuan. I obtained my Bachelor’s degree in Computer Science and Technology from the Yingcai Honors College at the University of Electronic Science and Technology of China in 2023, where I was fortunate to be advised by Prof. Xile Zhao.
I am currently working as a Research Assistant at MMLab, The Chinese University of Hong Kong (CUHK), under the supervision of Prof. Tianfan Xue.
My research interests lie in Computer Vision, particularly in image and video generation.
✨ News
- 2026-05: One paper is accepted to ICML 2026
- 2026-02: One paper is accepted to CVPR 2026
- 2025-09: One paper is accepted to NeurIPS 2025
- 2025-04: Two papers are accepted to SIGGRAPH 2025
- 2024-12: One paper is accepted to ICASSP 2025
- 2024-07: One paper is accepted to ECCV 2024
- 2022-06: One paper is accepted to ACM MM 2022
🔬 Research
* indicates equal contribution
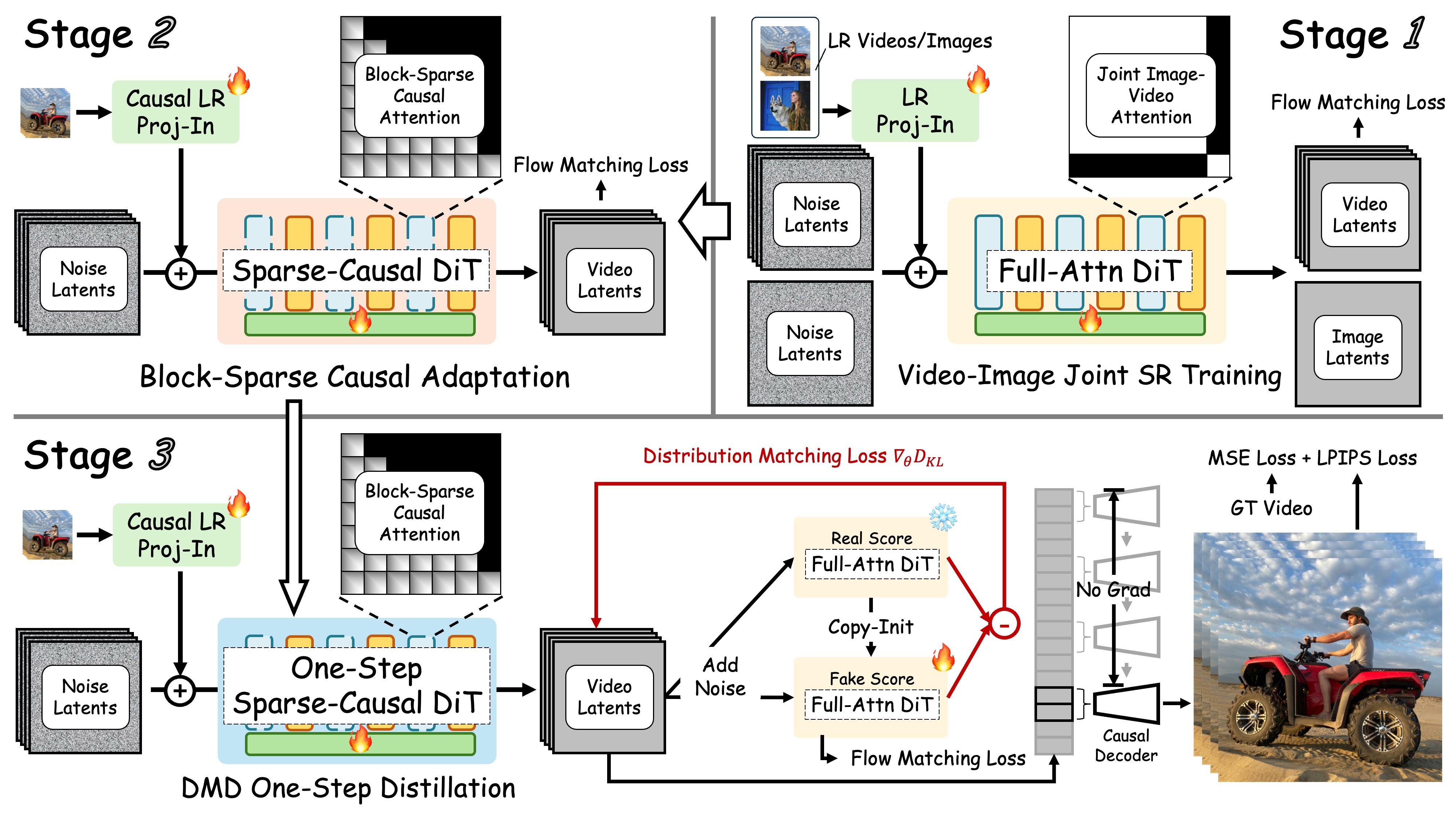 | Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan and Tianfan Xue Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [PDF] [Project Page] [Code]   FlashVSR is a streaming, one-step diffusion-based video super-resolution framework with block-sparse attention and a Tiny Conditional Decoder. It reaches ~17 FPS at 768×1408 on a single A100 GPU. A Locality-Constrained Attention design further improves generalization and perceptual quality on ultra-high-resolution videos. |
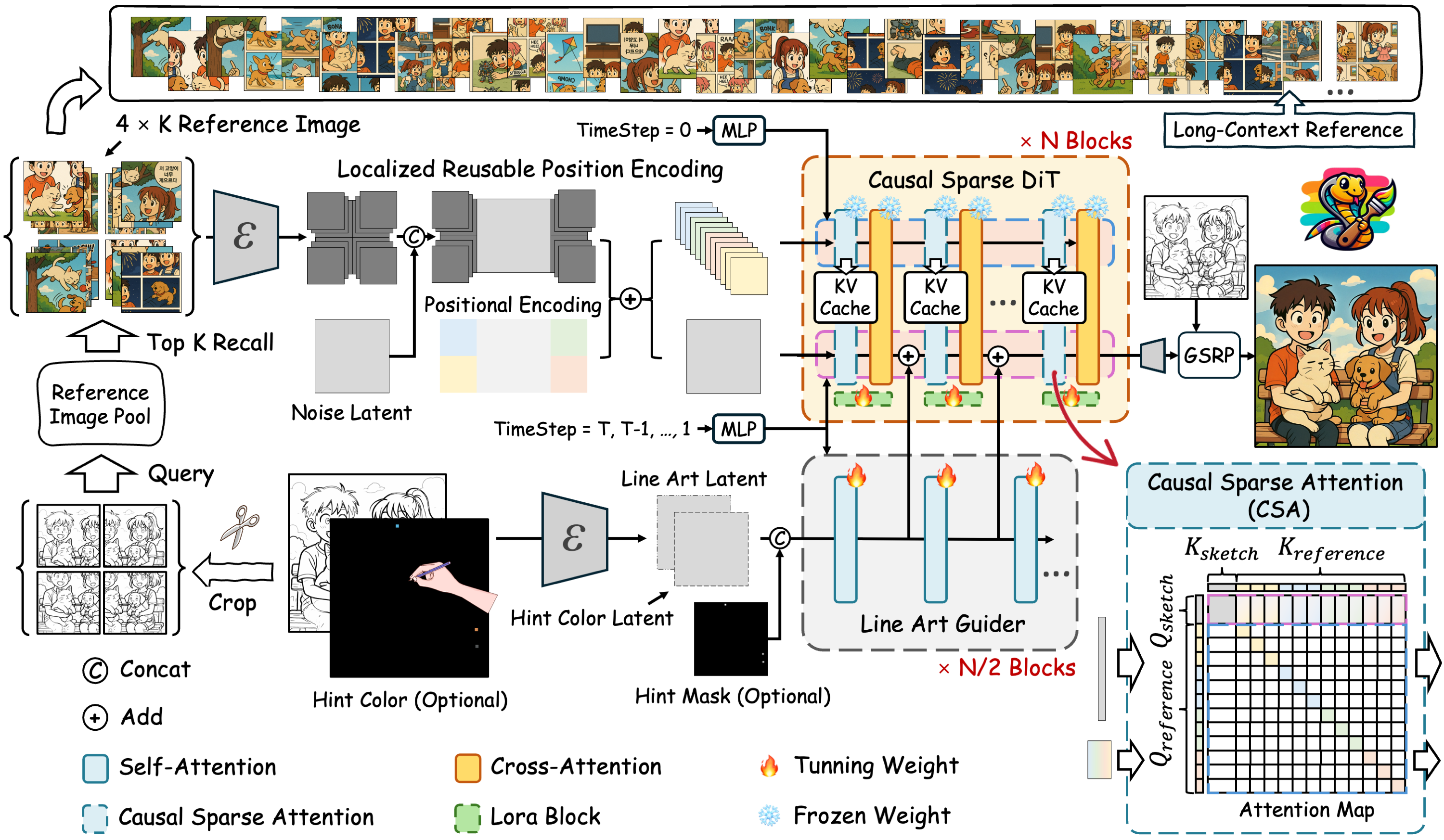 | Junhao Zhuang, Lingen Li, Xuan Ju, Zhaoyang Zhang, Chun Yuan and Ying Shan ACM SIGGRAPH (SIGGRAPH), 2025 [PDF] [Project Page] [Code]   Cobra is a novel efficient long-context fine-grained ID preservation framework for line art colorization, achieving high precision, efficiency, and flexible usability for comic colorization. By effectively integrating extensive contextual references, it transforms black-and-white line art into vibrant illustrations. |
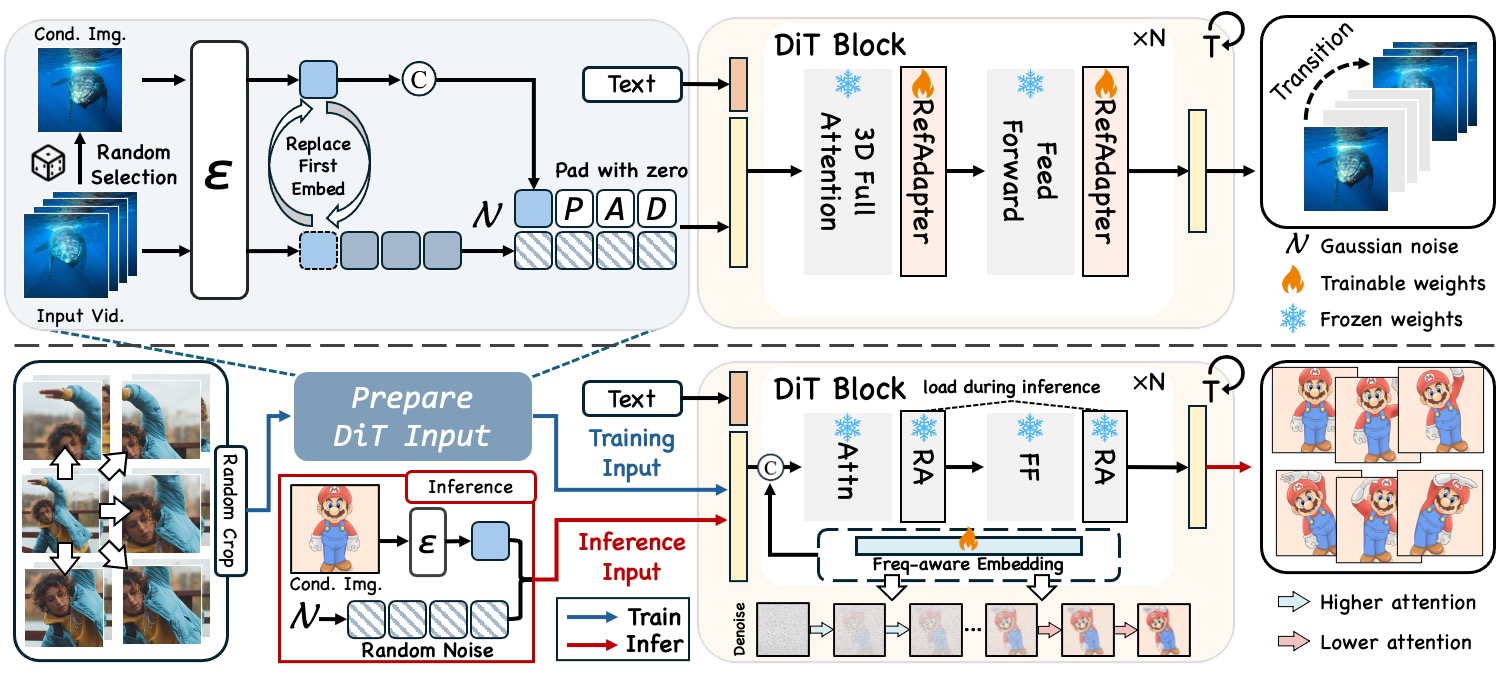 | Shiyi Zhang*, Junhao Zhuang*, Zhaoyang Zhang, Yansong Tang ACM SIGGRAPH (SIGGRAPH), 2025 [PDF] [Project Page] [Code]   We achieve action transfer in heterogeneous scenarios with varying spatial structures or cross-domain subjects. |
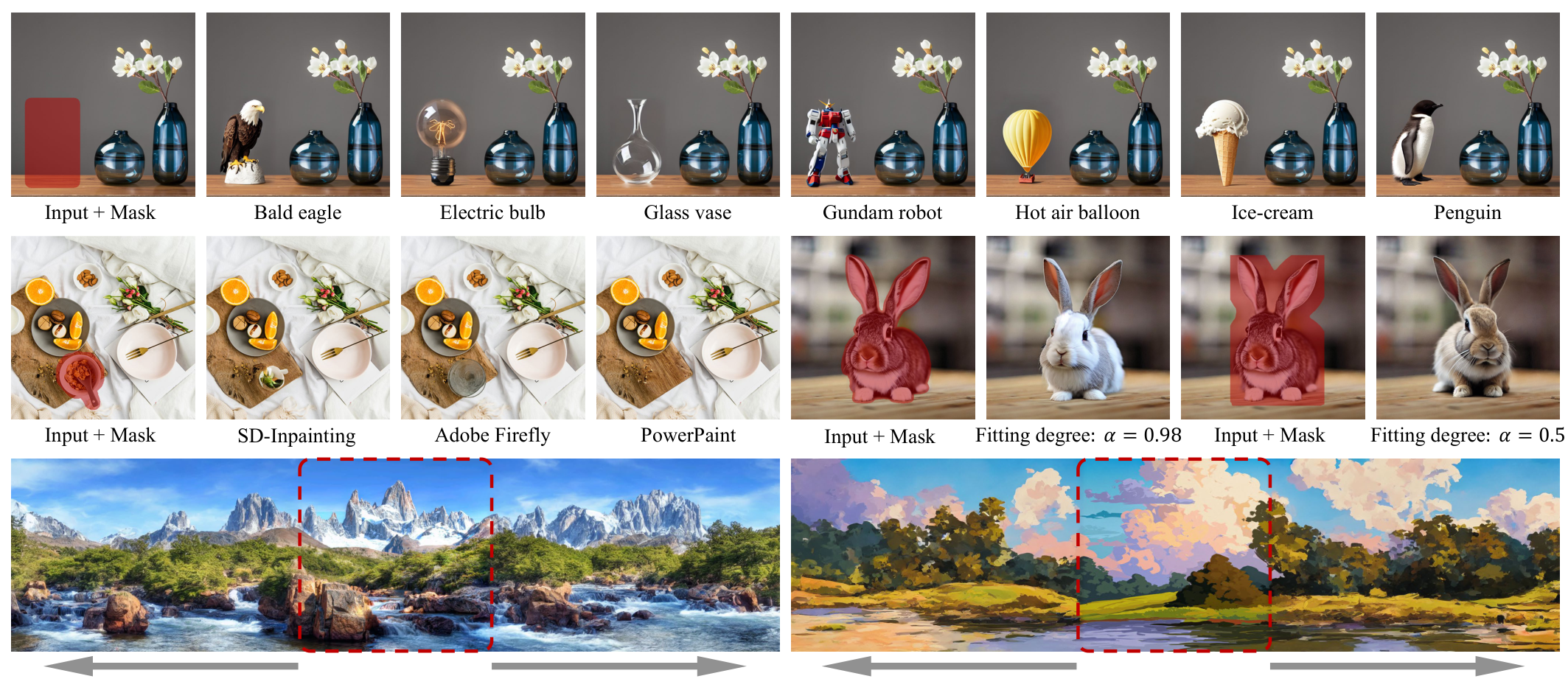 | Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, Kai Chen European Conference on Computer Vision (ECCV), 2024 [PDF] [Project Page] [Code]   PowerPaint is the first versatile image inpainting model that simultaneously achieves state-of-the-art results in various inpainting tasks such as text-guided object inpainting, context-aware image inpainting, shape-guided object inpainting with controllable shape-fitting, and outpainting. |
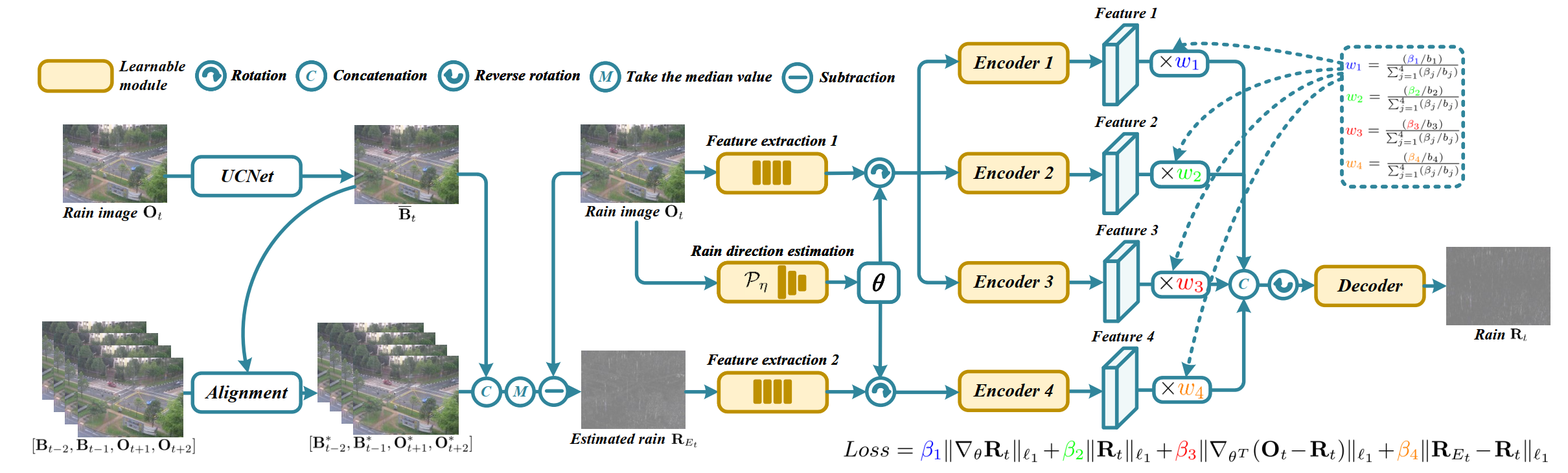 | Junhao Zhuang, Yisi Luo, Xile Zhao, Taixiang Jiang, Bichuan Guo ACM Multimedia Conference (ACM MM), 2022 [PDF] [Code] We propose the UConNet for image and video deraining. Our UConNet learns a relationship between trade-off parameters of the loss function and weightings of feature maps. At the inference stage, the weightings can be adaptively controlled to handle different rain scenarios, resulting in high generalization abilities. Extensive experimental results validate the effectiveness, generalization abilities, and efficiency of UConNet. |
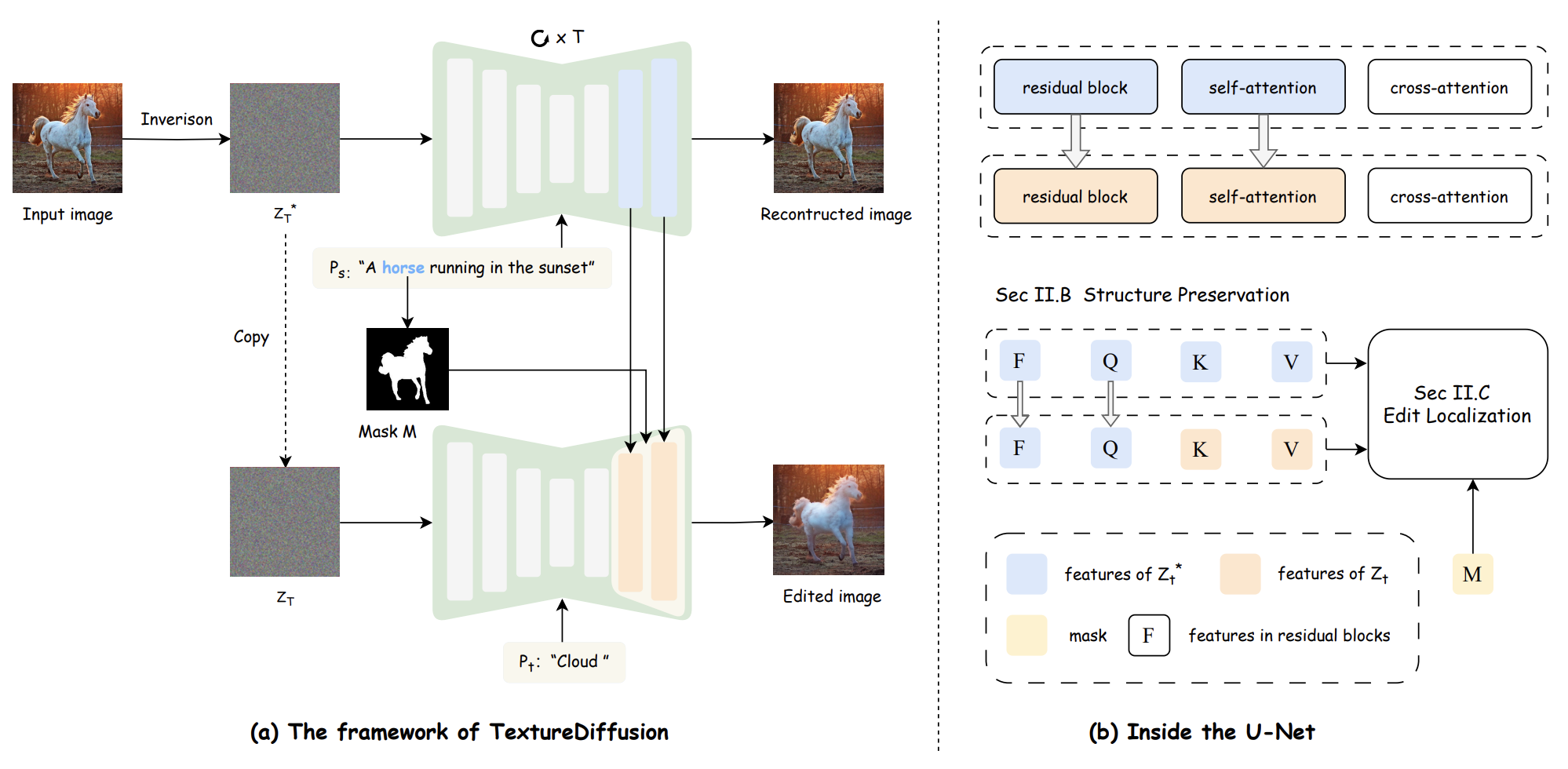 | Zihan Su, Junhao Zhuang, Chun Yuan International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2024, Oral [PDF] [Code] We proposed TextureDiffusion, a tuning-free image editing method applied to various texture transfer. |
 | Junhao Zhuang*, Xuan Ju*, Zhaoyang Zhang, Yong Liu, Shiyi Zhang, Chun Yuan, Ying Shan arXiv preprint arXiv:2412.11815, 2024 [PDF] [Project Page] [Code]   ColorFlow is the first model designed for fine-grained ID preservation in image sequence colorization, utilizing contextual information. Given a reference image pool, ColorFlow accurately generates colors for various elements in black and white image sequences, including the hair color and attire of characters, ensuring color consistency with the reference images. |
 | Zihan Su, Xuerui Qiu, Hongbin Xu, Tangyu Jiang, Junhao Zhuang, Chun Yuan, Ming Li, Shengfeng He, Fei Richard Yu Neural Information Processing Systems (NeurIPS), 2025 [PDF] [Project Page] [Code] Safe-Sora: a framework for embedding graphical watermarks into video generation, achieving state-of-the-art quality, fidelity, and robustness through hierarchical adaptive matching and a 3D wavelet-enhanced Mamba architecture. |
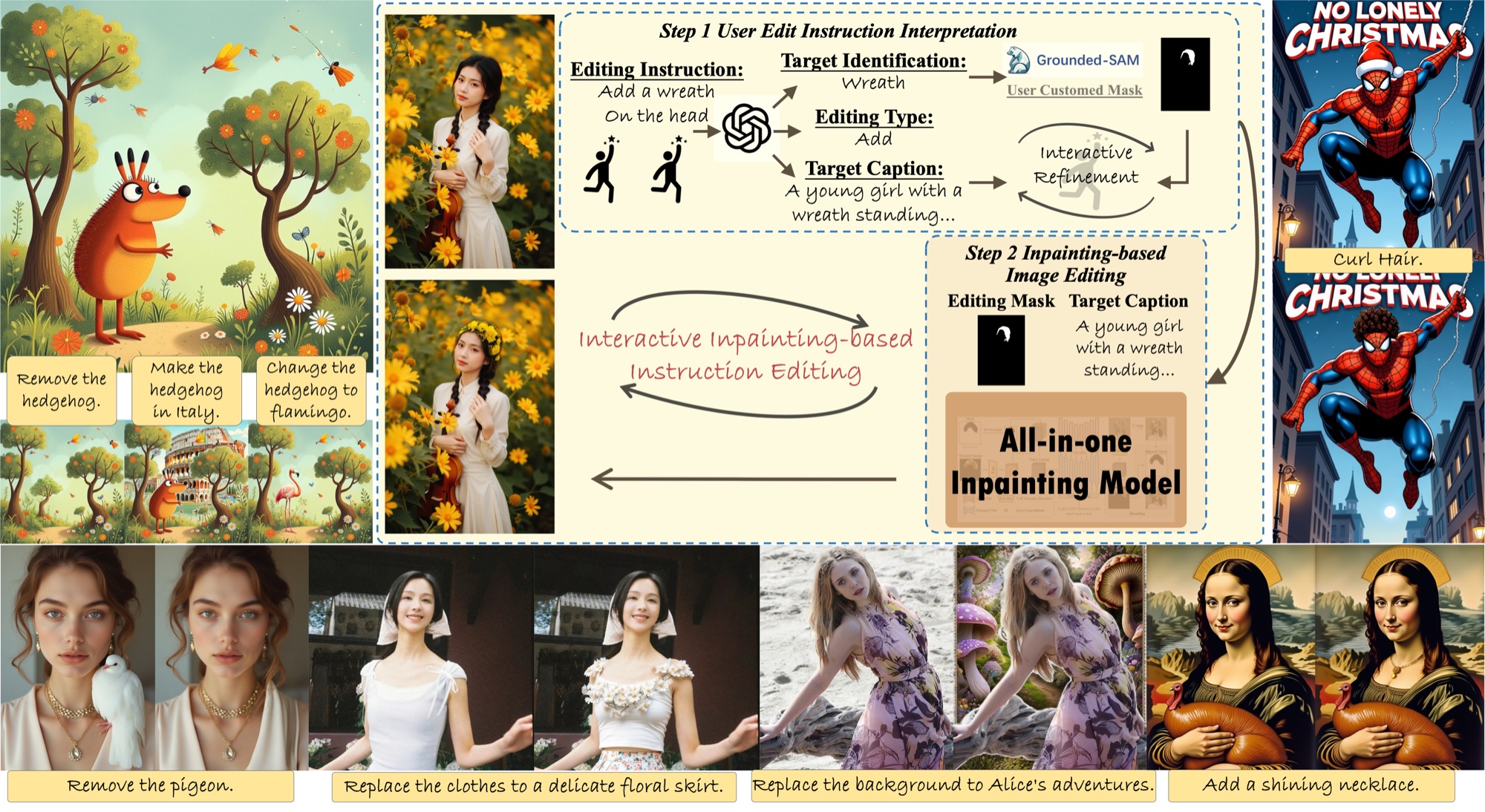 | Yaowei Li, Yuxuan Bian, Xuan Ju, Zhaoyang Zhang, Junhao Zhuang, Ying Shan, Yuexian Zou, Qiang Xu IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025 [PDF] [Project Page] [Code]   BrushEdit is an all-in-one image inpainting and editing framework that combines multimodal large language models (MLLMs) with the enhanced dual-branch diffusion inpainting model BrushNetX. It supports free-form instruction-guided interactive editing, achieves superior performance in background preservation and text alignment, and provides a user-friendly multi-round editing experience. |
💼 Experience
Kuaishou / KlingAI — Research Intern
Sep 2025 – Present
Supervised by Yunyao Mao, Xintao Wang
Topics: Video Generation
Shanghai Artificial Intelligence Laboratory — Research Intern
May 2025 – Sep 2025
Supervised by Shi Guo, Tianfan Xue
Topics: Video Super-Resolution · Diffusion Acceleration · Sparse Attention
Tencent, ARC Lab — Research Intern
May 2024 – Apr 2025
Supervised by Zhaoyang Zhang, Ying Shan
Topics: Comic Colorization · Video Generation · Diffusion
Shanghai Artificial Intelligence Laboratory — Research Intern
Jul 2023 – Feb 2024
Supervised by Yanhong Zeng, Kai Chen
Topics: Image Inpainting · Diffusion