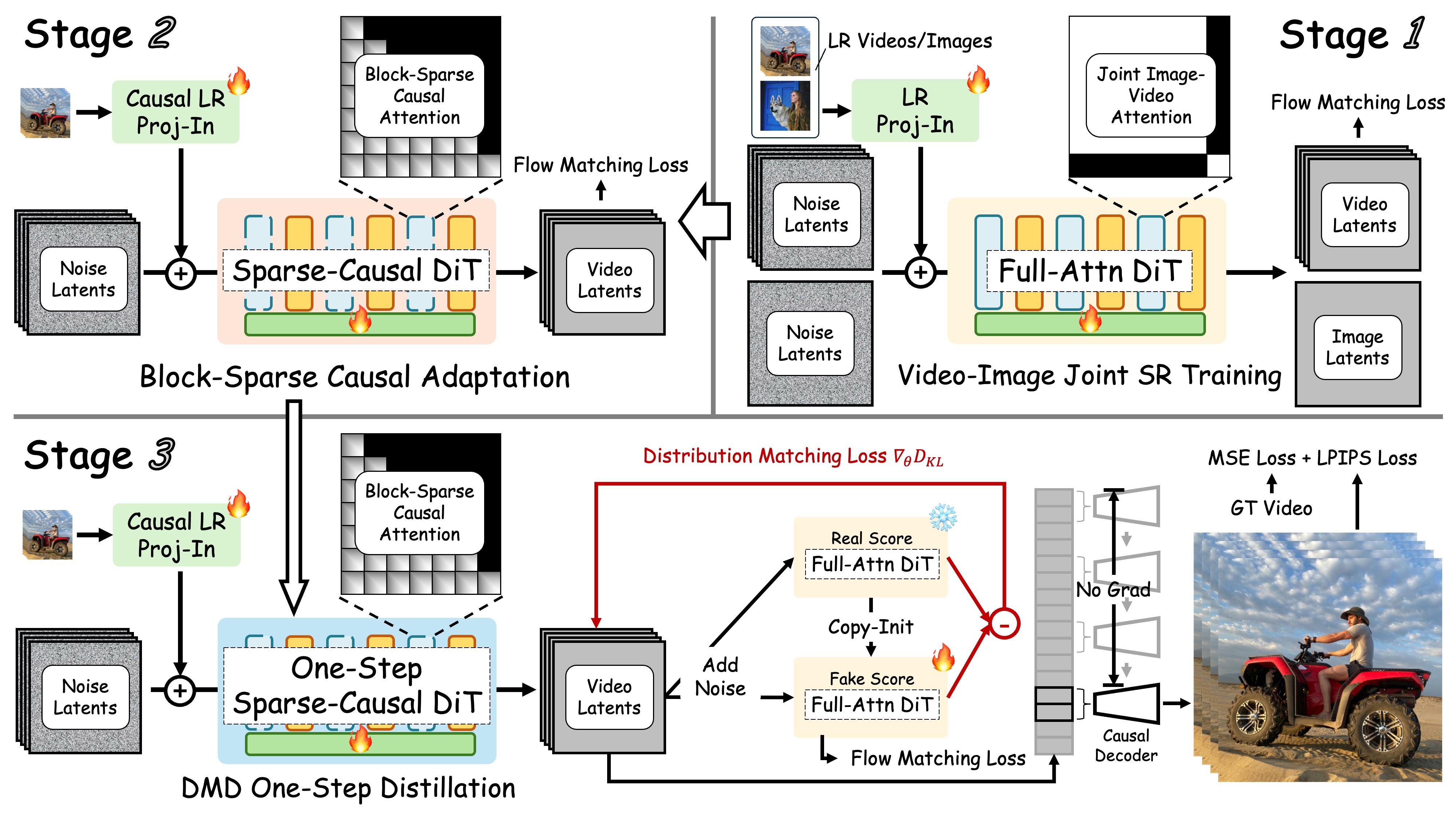
We distill a full-attention teacher into a sparse-causal, one-step student for streaming VSR. The model runs causally with a KV cache and uses locality-constrained sparse attention to cut redundant computation and close the train–inference resolution gap. A Tiny Conditional Decoder (TC Decoder) leverages LR frames + latents to reconstruct HR frames efficiently.
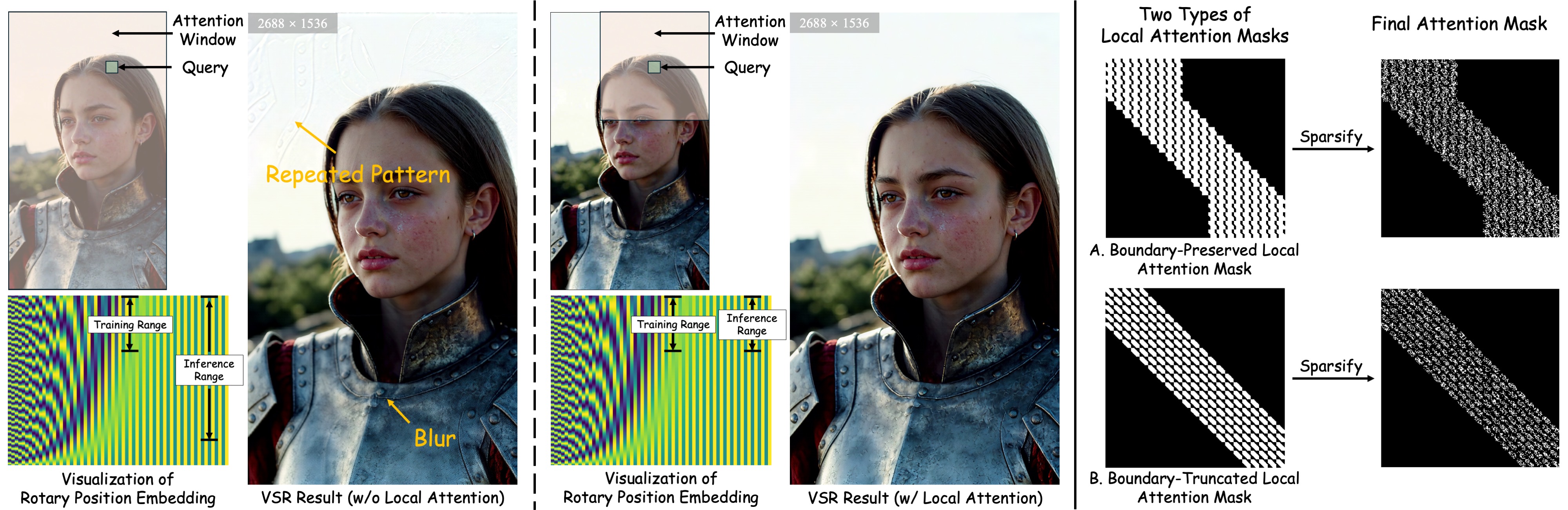
When models trained on medium-resolution data are applied to ultra-high-resolution inputs, they often exhibit repeated textures and blurring. This degradation stems from the periodicity of positional encodings—for instance, in RoPE, when inference spans exceed the positional range encountered during training, the rotational angles wrap around periodically, causing aliasing and pattern repetition along specific spatial dimensions. To mitigate this, we constrain each query to attend only within a local spatial window, ensuring that the positional range during inference remains consistent with that seen in training. Building upon this locality constraint, we further adopt sparse attention that concentrates computation on the top-k most relevant regions rather than across the entire spatial dimensions, significantly improving computational efficiency and perceptual quality at high resolutions.
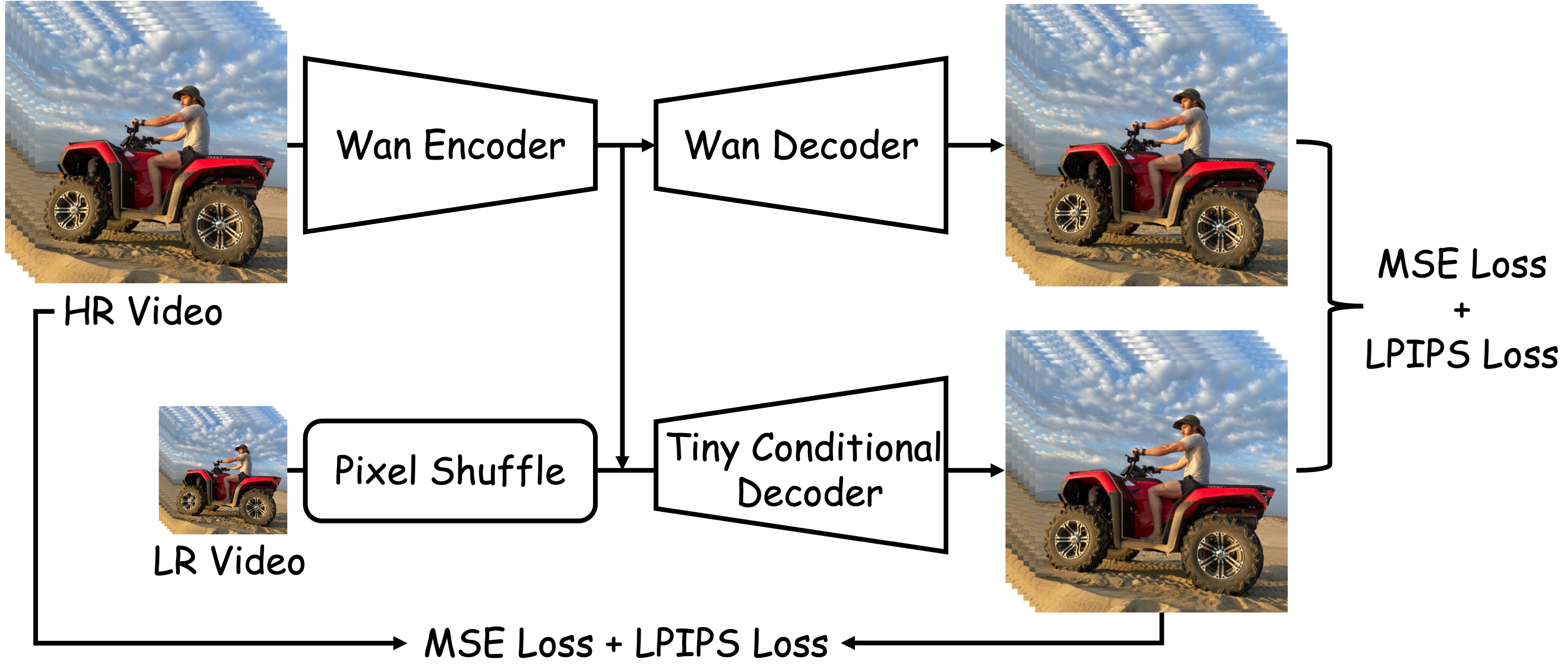
Compared with the original WanVAE decoder, the proposed Tiny Conditional (TC) Decoder takes not only the latent representations but also the corresponding low-resolution (LR) frames as additional conditioning inputs. By leveraging these LR signals, the TC Decoder effectively simplifies the high-resolution (HR) reconstruction process, achieving a 7× acceleration in decoding speed while maintaining virtually indistinguishable visual quality from the original VAE decoder.
We construct VSR-120K, a large-scale dataset designed for high-quality video super-resolution training. The dataset contains around 120k video clips (average >350 frames) and 180k high-resolution images collected from open platforms. To ensure data quality, we filter all samples using LAION-Aesthetic and MUSIQ predictors for visual quality assessment, and apply RAFT to remove segments with insufficient motion. Only videos with resolutions higher than 1080p and adequate temporal dynamics are retained. After multi-stage filtering, we obtain a clean, diverse corpus suitable for large-scale joint image–video super-resolution training.
Release note: We are currently organizing (curating) VSR-120K and will open-source the dataset in a future release.
Drag the vertical bar: left = LR, right = Ours.
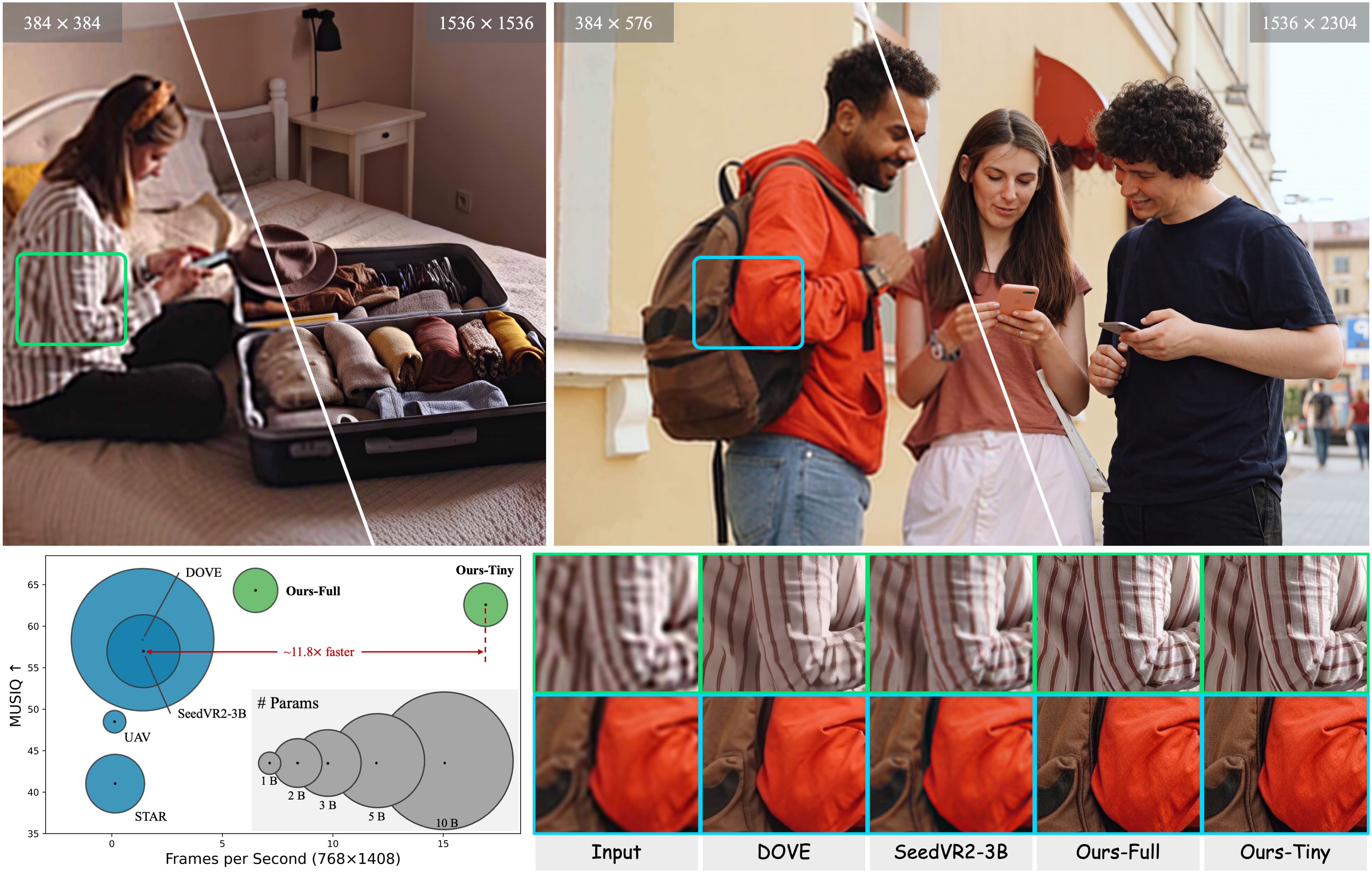
View detailed comparisons with other methods and ablation studies
@article{zhuang2025flashvsr,
title={FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution},
author={Zhuang, Junhao and Guo, Shi and Cai, Xin and Li, Xiaohui and Liu, Yihao and Yuan, Chun and Xue, Tianfan},
journal={arXiv preprint arXiv:2510.12747},
year={2025}
}